You’ve got piles of files. I’ve got newer piles of files. How can you catch up with me most efficiently?
This is the delta update problem and there are competing algorithms for solving it. Unfortunately there’s not much out there that compares them, so today we’re going to fix that. We’ll take a look at the “classic” binary delta approach as used by Sparkle (we recently added support for these deltas), Chrome’s Courgette and Zucchini, the Windows MSIX block map, Docker, ChromeOS and the approach taken by casync. These are all different schemes, which gives us good coverage of the ideas in this space. These algorithms have critical importance to the UX of software updates. Plus, they’re just interesting! So let’s dive in and take a look.
Delta sizes
Let’s get the most burning question out of the way: how big are delta updates to your app going to be, when computed by Conveyor? Especially when using the aggressive updates mode where any available updates are applied immediately on every app start, delta size is critical.
The answer will depend on what kind of app you’re shipping and the nature of the differences between versions, but
briefly, for the Electron hello world app (conveyor generate electron hello-world) a one line change to the JavaScript
yields a download on Windows of about 115 kilobytes, and a delta on macOS of about 32 kilobytes. That’s so small the
update process is dominated by server latency, so to optimize make sure you serve from a fast CDN without redirects
(i.e. not GitHub Releases).
Still, there are some caveats. The delta a single line source change yields will depend partly on any packers or optimizers you use, as with those small changes can ripple into much bigger changes in the files you’re actually shipping. Also, it isn’t easy to compute the actual size of a delta on Windows. Showing this size might be a useful feature we add in future. Finally, for JVM apps the delta computation isn’t optimal: modules often have their version numbers in the JAR file name and Conveyor doesn’t yet track properly changes that occur both in file names and contents simultaneously. There’s scope for us to optimize here.
Even though those are small downloads, it’s still a lot larger than the few bytes you may have expected from a single line change. Where does the overhead come from? And why is it so different between Windows and macOS? The answer is a mix of file format overhead, changes to metadata files containing the version number, patch vs block based algorithms (discussed below), and above all the fact that rebuilding the app re-signs all the native code files. This is because code signatures are timestamped and thus can’t easily be re-used. That last factor places a hard minimum limit on how small a delta update can be depending on how many libraries and executables your package contains, as each one will have a small section that changes every time even if no input files have changed. This could be optimized further, but at some point we hit diminishing returns.
Now let’s dive deeper to understand how delta update schemes work.
Sparkle deltas
The most obvious method to upgrade a user from version 1 to 2 is to just redownload the entire app all over again. The Sparkle update engine that gets automatically added to the macOS version of your app when you package it with Conveyor will do this as a last resort if it can’t use a more efficient approach.
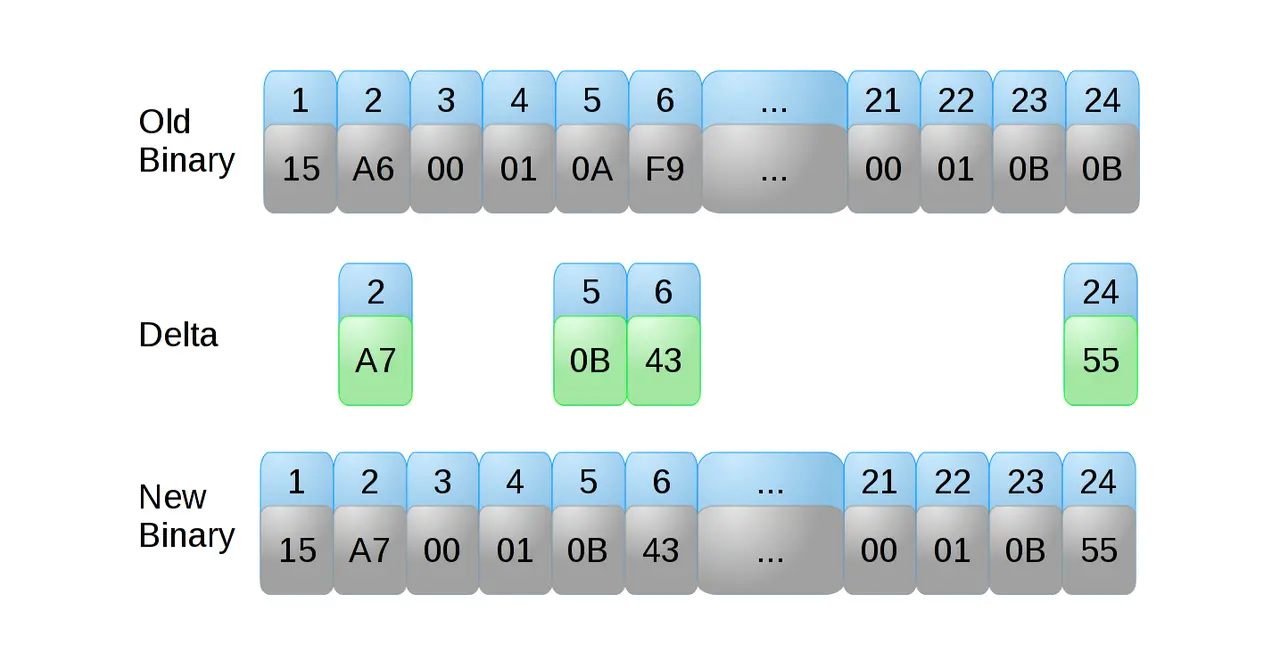
Delta patches are the next most obvious method. A Sparkle delta is a custom binary format that encodes a series of commands:
- Delete
- Extract
- Clone
- Modify permissions
- Patch
Some of these commands can be combined into a single command. For example, modify permissions can be combined with clone, extract or patch. The patch file also contains possibly compressed byte arrays to which commands can point. Symlinks are encoded as a file to be extracted with a special mode bits. In this way a file that e.g. gets moved and then made read-only in the new version can be expressed concisely.
Sparkle patch files also contain checksums of both “before” and “expected after” states. This is an important safety check that stops the engine from mangling a program that’s been edited y the user. If the patch doesn’t yield the intended files then Sparkle tosses the result and redownloads the app from scratch.
A delta can be expressed just using the first four commands, as a changed file can always be replaced with an extract command. In practice most changes between versions of an app are to the contents of an existing file, and some of those files can be large. For example, Electron is mostly a single library of about 150MB in size. For this there patch, which points at a bsdiff.
bsdiffs
In classic UNIX style the “bs” in bsdiff doesn’t actually stand for anything. It was put there to avoid namespace conflicts with other programs that were already camping on the name “bdiff”, but that’s OK. A good backronym is “binary subtraction diff”, because this is the core idea that makes bsdiffs efficient.
Just like how a Sparkle delta is a series of commands, so too is a binary patch. The simplest type of patch is a series of copy and insert commands. Copy commands re-use data from the old version on disk, and insert adds new data. A bsdiff extends this idea by replacing copy with add. In an add command, a data block is reused from on the existing version but then matched with a byte array of the same size from the patch, called the difference. Each byte from the old version is added to a byte from the difference before being written to the new version.
This technique allows for approximate matches, which helps when the new file is mostly the same as the old except for a few locations that have been incremented or decremented. This is very common in compiled executable code, which is full of offsets and pointers to locations elsewhere in the file. If a function gets some extra code and expands you might think this would translate to a single insert command just like it would in a textual diff, but in reality it doesn’t because the call sites for all the other moved functions will change too. This bloats patches. By allowing a copy operation to modify the bytes as they get copied this type of scattered “a little tweak here, a little tweak there” difference can be encoded much more efficiently. The difference blocks will mostly be zero bytes, so along with the commands they’re compressed using bzip2 and then decompressed on the fly as the patch is applied.
You can learn more about bsdiff in Colin Percival’s paper.
Courgette and Zucchini
The bsdiff scheme just described works well, but still needs to encode the difference for each internal pointer in the executable file. This is a deliberate choice which means bsdiff doesn’t need to know anything about platform specific file formats, simplifying the scheme and making it more portable.
The Chrome team wanted to speed up the process of distributing updates to their users, and one of the quickest wins was to reduce the size of their binary deltas. If they could reduce their patch files in size by 10x they could transmit 10x more of them in the same amount of time without needing more bandwidth. And unlike Colin, they weren’t constrained by available time or funding. The result was Courgette, which successfully reduced Chrome patches by an order of magnitude. Courgette was later replaced by Zucchini which is substantially the same idea.
All these algorithms are specialized for binary code, and in fact they build on bsdiff as a foundation. The improvements come from pre-processing the input files in a process they call “disassembly” (this isn’t a real disassembly but the idea is vaguely related). Disassembly understands each platform’s native file formats for programs and shared libraries (PE on Windows, ELF on Linux, Dex on Android but not MachO on macOS which is unsupported), and converts these files to an intermediate form which is then fed to bsdiff as normal. On the client side the existing code on disk is run through this same disassembly process, the binary patch is applied to the disassembled form, and that form is then “reassembled” back to native code. The disassembled form of the file is designed for diffing, so yields smaller patches at a cost of more CPU time. As Chrome always applies patches asynchronously in the background the additional CPU cost is taken to be irrelevant compared to the bandwidth savings.
If you think about it, the reason a small change to a program yields a small git commit is because all the references in source code are based on names, not physical offsets into a file. To better understand what a native program looks like after compilation, imagine that to call a function you had to type in the exact line number of the function you’re calling. Obviously, if you added some lines of code near the start of a file you’d have to find all the calls to any function that came after your change and update them all. Courgette/Zucchini replace the internal pointers in a binary file with indexes into an array of offsets computed by the patching process, giving each block of code a numeric “name”. The offset table can then be adjusted independently with a more compact encoding, before the offsets are substituted back into the code.
This somewhat obsolete diagram shows the general workflow, but bear in mind that modern Zucchini doesn’t seem to use an “adjustment” step in the same way as Courgette did.

The main disadvantage of all these algorithms, bsdiff included, is that it’s very slow and RAM intensive to compute the delta file. Because the delta is computed once but downloaded many times that’s usually an acceptable price to pay. In some cases though it may be a problem. For example, if you’re regularly releasing new versions of a program with big files from your laptop, as you might well be doing if releasing an Electron app using Conveyor, then the RAM and CPU overhead added to the release process could become prohibitive. Even when using continuous integration servers, RAM/CPU aren’t free.
The Sparkle engine doesn’t support Courgette/Zucchini, but even if we did add such support it’s possible that the sheer slowness of computing the diffs would upset you. For example diffing two versions of Chrome with Zucchini can take 20 minutes and many gigabytes of RAM. As you’d want to repeat that for several platforms, releasing would become a ponderous process.
There’s another problem. When users only run your app occasionally it’s possible that there will have been more than
one release since the user last got a chance to run updates. Because a binary delta encodes the difference between
exactly two file trees, you really want to compute a delta for the last several releases, not just one. The number
of Mac/Sparkle patches to compute is controlled by the app.mac.delta config key in your conveyor.conf file and
defaults to five. Because there are at least two separate builds of your app (one for each CPU architecture)
each release will compute and upload 10 patches, so patch calculation time is a meaningful constraint.
Block maps
For Windows Conveyor generates MSIX packages. This is the native package format of Windows 10/11 and supports a very different form of delta updates based on a block map. A block map is simply a list of hashes of chunks of each file in the archive (MSIX files are zips). Each block is about 64kb in size. When a new version of the app is released the block map for the new version is compared to that of the old version and the changed blocks are fetched either using HTTP range requests, or by reading them from pre-existing files on disk.
This scheme is simple yet has some very desirable properties:
- It’s very fast to compute and use block maps.
- Windows indexes the block maps of every installed package, so data can be reused from arbitrary programs on disk and not just the current version of whatever is being updated.
- Pre-existing blocks can be used even for fresh installs of programs if the user has other packages installed with similar files, e.g. a near enough version of Electron. So this scheme can accelerate the first run of a program too.
- No additional files need to be uploaded to enable this feature, just an index in the package itself. By implication delta updates are possible no matter how far behind the user falls.
The big downside is efficiency. Changing a single byte triggers a transfer of the entire block. Worse, if you insert or delete even one single byte anywhere in a file then all the blocks after that point will change. This scheme will thus often end up transferring more data than necessary. A smart enough toolchain could vary the size of blocks using a rolling hash to avoid this problem (see below), but in practice nothing does yet. We may experiment with variable chunk sizes in future.
There are also some disadvantages specific to Microsoft’s implementation:
- The deployment engine requires HTTP range requests and will simply fail if the server doesn’t support them. This is rarely an issue for real production quality web servers but can cause issues when using simple local web servers, like the one built in to Python.
- The block map is encoded as XML even though it consists primarily of numbers and hashes. This makes it much larger than it needs to be.
- The block map points into compressed data, so the MSIX ZIP has to be constructed in a very specific and careful way that allows seeking within the compressed streams. This isn’t a problem for Conveyor which implements its own zip library, but it does mean that you can’t use standard zip tools to create them.
- Because the block map and signature data are included inside the zip, these special files have to be the last added to the archive. In turn that means Windows has to first locate and download the map. This requires a bunch of range requests to seek to the end of the zip, read it backwards, then locate the offset of the block map from the zip central directory and process it. The Windows implementation is inefficient and makes more requests than it needs to, which can add latency on web servers that respond with many redirects (e.g. GitHub Releases).
Overall the blockmap scheme works OK and imposes minimal requirements on client and server. It sacrifices efficiency to get simplicity, yet is still capable of features not found in most schemes.
OSTree
In theory nothing stops block maps from being combined with more conventional binary deltas to deliver the strengths of both approaches. This is the approach taken by a format called OSTree, which is used by the Flatpak system on Linux. It can use a mix of hashed files and binary deltas. An OSTree repository is conceptually similar to a git repository, meaning that directories are represented as metadata files containing the hashes of the content files, and those are then stored under files named after their content hash. This format is quite inefficient in terms of HTTP requests, as it can yield in the worst case one request per file on a new install.
OSTree also doesn’t index the individual blocks of files, making an implicit assumption that programs are split into many small files. This unfortunately doesn’t hold for some programs, like Electron apps.
To mitigate these issues OSTree repositories can also contain binary deltas. These are computed using the bsdiff algorithm and the format of a delta is conceptually similar to Sparkle’s (but different). Thus Flatpak has one of the most complex repository formats, combining a custom way to encode software files on the server with an optional delta encoding. For the intended use case of serving operating system updates this isn’t a bad approach, but does mean that flatpakked apps can’t be downloaded as normal archives.
ChromeOS
Yet another blend of block map and bsdiff can be found in ChromeOS. Here the install partition is treated as a single giant file split into 4kb blocks. As with Sparkle, the delta is a series of operations in which new blocks can be unpacked from the delta file or bsdiff can be used to update a block in place.
This may seem rather indirect - why not just compute a bsdiff for the entire disk - but it has to be done this way because the memory requirements needed to compute or apply bsdiffs rapidly get out of hand as files get larger. bsdiff’s worst case memory complexity can be 17x the size of the inputs! This rapidly makes it intractable to compute or apply diffs to entire disk images.
casync
casync is a project by Lennart Poettering, the mind behind systemd. It combines the willingness to hash blocks (chunks) of files seen in MSIX with a Flatpak/OSTree git-inspired style repository layout, but with a couple of twists:
- The block sizes aren’t fixed. Instead they are computed using a “rolling hash” (buzhash). A rolling hash looks for boundaries based on the content in the stream, which makes the division into blocks somewhat resistant to insertion or deletion of bytes.
- Files are glued together before the whole stream is split into blocks. This means that request sizes to the server are always roughly similar, even for trees that consist of many tiny files.
Because it doesn’t care much about actual files or directories casync can also be used to encode and transmit differences between different disk images, thus making it useful for full OS updates as well as individual apps. Like MSIX casync is also capable of using already downloaded data to optimize transfers, although unlike Windows it won’t automatically discover and use pre-existing apps as “seeds”.
You may be wondering how this differs to rsync. The main difference from an end user’s perspective is that rsync requires special servers that do fairly intense computation, whereas a casync repository (like for all the schemes here) can be hosted on ordinary HTTP servers and thus ordinary CDNs.
Docker
Although it doesn’t target the desktop, our final stop on this tour of delta update schemes must be Docker. Docker images are internally a collection of tarballs which are stacked on top of each other. Later tarballs can override earlier ones, thus forming a stack of deltas starting from the empty tree.
This scheme has the advantage that it’s very simple. There’s no explicit delta encoding step, and the file formats used are widely supported. The tar format can’t express deletions thus requiring the addition of “tombstone” files, but otherwise you can work with Docker images without using Docker itself quite easily.
The big disadvantage is that it’s inefficient. If you change a single byte in a file then the entire layer has to be redownloaded. Worse, if a file is replaced then both versions of the file will be downloaded in full, as the earlier layer must still be fetched in its entirety. Finally whether layers actually encode deltas well or not is highly dependent on the exact sequence of commands used to build the image, and whether the apps you use happen to agree on what base images to use. Docker layers are effectively checkpoints in which each delta represents the difference created by running each command, so apparently no-op changes to the Dockerfile can yield big changes in layer size.
Overall Docker wins on being simple, fast and is clearly good enough, especially for servers where bandwidth and disk space are cheap. For desktops where bandwidth and latency are at a premium more sophisticated encodings rule the day.